
MIHAI JALOBEANU
In pursuit of dexterity and physical intelligence for general-purpose robots.

Building Physical AI
I am a research architect, technology strategist, and hands-on engineer. I operate across the entire spectrum of Embodied AI, from mapping industry trends to engineering real-time control systems, agentic HRI, and autonomous cognitive architectures. I believe this technology will fundamentally reshape society for the better, and history will look back at this decade as the moment it all started. I explore this transition, and the strategies required to get us there, on my blog: Mihai Jalobeanu – Medium
I am the CEO of dexman.ai, a company I founded in 2023 with the mission to make all robots universally accessible and broadly useful. We are building a “Cursor for Robotics”, a hardware-agnostic system called Dex that enables anyone to teach machines new tasks intuitively through language, gestures, and demonstrations. Check out our YouTube videos, and learn more at https://dexman.ai

Background
I love making software that interacts with the physical world. I tend to dream big, and push hard. I’ve been building and shipping software for 25 years, from robotics control to enterprise systems, from interactive art installations to Internet-scale services, from developer tools to foundation models for robotics. I got my PhD in AI and Robotics mid-way through my career, and switched to working on AI full-time in 2012, just in time for the Deep Learning revolution. My work since then has been motivated by the broad goal of building agents that achieve human-level performance on motor and perceptual tasks in the physical world. Prior to dexman.ai, I worked at Microsoft Research for 11 years on Robotics, Embodied Intelligence, Reinforcement Learning, Representation Learning and Foundation Models for Robotics. The list of papers and patents I authored and co-authored is available on Google Scholar.
ROBOTICS PROJECTS

Shared intelligence
At dexman.ai, our goal is to make robots accessible to everyone, including non-technical users. Thus, we cannot expect users to write any code to program the robot. On the other hand, the robot cannot magically perform every task right out of the box either (yet). Shared Intelligence is the idea that we eliminate both issues by enabling a dialog between user and robot. The user explains the task, watches the robot attempting it, and provides feedback. The robot, on the other hand, can explain its understanding and reasoning as it attempts the task. The user might simplify the setting, ask the robot to focus on a sub-task, provide more detailed instructions and so on, until the robot can perform the task satisfactorily. Our key contribution is to use this dialog to generate an accurate self-assessment procedure for labeling robot experiences. The system can use it to automatically collect and label on-task data through practice, even though its zero-shot performance might be relatively low. The collected experiences are used to self-train dedicated, task-specific models that can perform the task with high reliably.

Zero-shot manipulation
How far can we get with just pretrained LLMs/VLMs (large language and vision models), without any fine-tuning? Turns out pretty far: our neuro-symbolic system can execute many kinds of novel tasks in new environments, manipulating unseen (open-vocabulary) objects completely zero-shot, just from language instructions. We use a segmentation model (e.g. SAM) to ground a VLM (GPT4 or Llama3.2) with visual input from multiple cameras. A neuro-symbolic reasoning process transforms the task description into a sequence of skills, which are executed by the robot using depth perception and closed-loop force-based control. The same neuro-symbolic process is used to decide whether each skill succeeded, and to retry or change strategy if necessary. Videos of various tasks performed zero-shot, including playing tic-tac-toe, are available on the dexman.ai YouTube channel.

Foundation MODELS
Training visuomotor Foundation Models for robotic manipulation requires a lot of data, much more than available in the form of on-robot demonstrations. If we could somehow use arbitrary YouTube videos of people performing manual tasks, and figure out how to cope with the absence of action and proprioceptive information, the amount and diversity of available data would radically change. That’s precisely what we did in this work. We devised a method to combine internet videos, teleoperation demonstrations and robot experiences to pretrain a single visuomotor model, and showed that our model generalized better and learned new tasks faster than models trained with just demonstration data (see our PLEX and HEETR papers). However, it turns out that data quality is equally (if not more) important, so at dexman.ai we set out to collect one of the largest robotic manipulation datasets intentionally designed to imitate the dexterous skill acquisition of babies and toddlers. We call the resulting foundation model the Artificial Motor Cortex (AMC).

learning From PLay
Can learning from direct interaction with a physical environment lead to better latent representations? Interaction can reveal object properties that are not observable through vision alone: density, elasticity, friction etc. Interactions can also reveal some of the key properties of the physical world that underpin human intuition and predictive ability: object identity, object permanence and causality. In this work, we studied the extent to which such aspects can be incorporated, implicitly or explicitly, as latent factors of the learned representation; whether the resulting representation benefits from learning with full trajectories; and whether the representation generalizes across a multiple tasks. The work uncovered better strategies for combining reinforcement learning with a learning curriculum designed for this purpose, and led to the development of a novel simulation environment where physical factors could be easily manipulated and disentangled (see paper and repo).

Haptic recognition
Humans use haptic perception to recognize objects when visual perception is insufficient or unavailable, for example to find keys in a purse or a light switch in the dark. Can a robot learn to recognize objects just by touching and interacting with them? Equipped with just a wrist-mounted force-torque sensor and a two-finger gripper, our robot was able to extract a significant amount of information, and learned to recognize every one of the 50 different objects in the dataset, with over 80% success rate. More importantly, it succeeded where visual sensing typically fails: it could differentiate between object instances with identical visual properties, such as full or empty bottles; it could resolve ambiguities caused by reflective or transparent materials; it was able to identify invisible properties such as mass and compressive strength; and could provide accurate size information.

RoMAn
Roman is a Python library that enables vision-based online learning (e.g. online RL or self-supervised learning) on real robotic arms (see repo). The key capability is the implementation of a real-time layer that combines force sensing with various types of control. It detects and reacts to collisions with the environment, allowing execution of imperfect policies in a relatively safe way. It supports real robots (Universal Robots CB and e-series) equipped with force-torque sensors and grippers, and includes a matching PyBullet-based simulator. A key design goal was to share most of the code between the real and simulated robot stacks, to ensure reproducibility of behavior, so a common real-time module is translated to URScript when executing on the real robot, and to Python when running the simulator.
\psi
Platform for Situated Intelligence (\psi) is an elegant and powerful open framework for development and research of Embodied AI systems, written in C#. It includes an incredibly fast stream-based runtime that runs computation graphs with maximum parallelism, allowing for multi-threaded, multi-process (with shared memory) and multi-machine (with UDP) configurations. The runtime can stream data without performing any memory allocations at steady state, a critical property for achieving consistent throughput. It uses event-time propagation and synchronization to enforce causal coherence, prioritize execution, handle cycles and provide shared-state synchronization. It comes with a declarative programming model and language-integrated operators for aggregating arbitrary, stateful computation modules into stream-processing graphs. And it provides an incredibly rich, customizable and extensible set of visualization and annotation tools (audio, image, point clouds and much more), for both online and offline data. That’s a lot to unpack, so check it out here: repo, paper, paper.

squeaky
This was a fun little project designed to demonstrate the real-time properties of \psi. The wheeled platform was built for less than $100. \psi was running on-board, on a Surface tablet mounted on top. Real-time obstacle detection, including negative obstacles (drops), enabled the robot to move fast on a table without falling off the edge. Language understanding provided the means to command the robot, and speech-to-speech chat provided access to Wikipedia information. All before Chat GPT.

Program synthesis
Can a robot learn a new task from a single human demonstration, and can we trust the outcome of the learning process? One possible approach, employed here, is to restrict robot behavior to a set of well-tested visuomotor skills, and use demonstrations to generate human-readable task execution programs over these skills. The programs can then be rapidly inspected, verified and refined, incorporating further demonstrations if necessary. Using a program synthesis approach, we were able to generate programs from just one or a handful of demonstrations performed using a touch-based tablet interface. The use of the touch-based interface increased their expressiveness, reducing the number of demonstrations required compared to kinestetic teaching or teleoperation of a real robot.
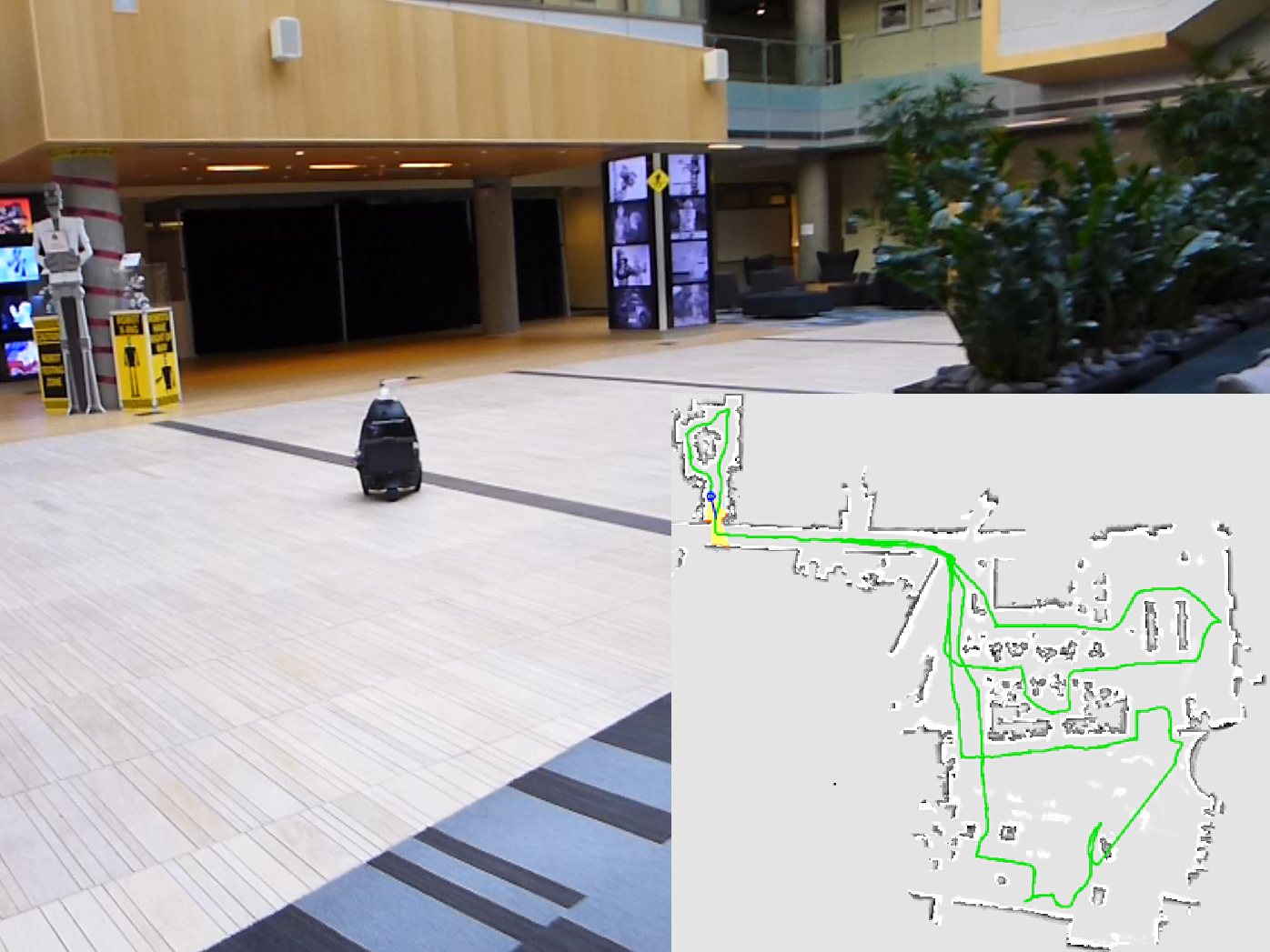
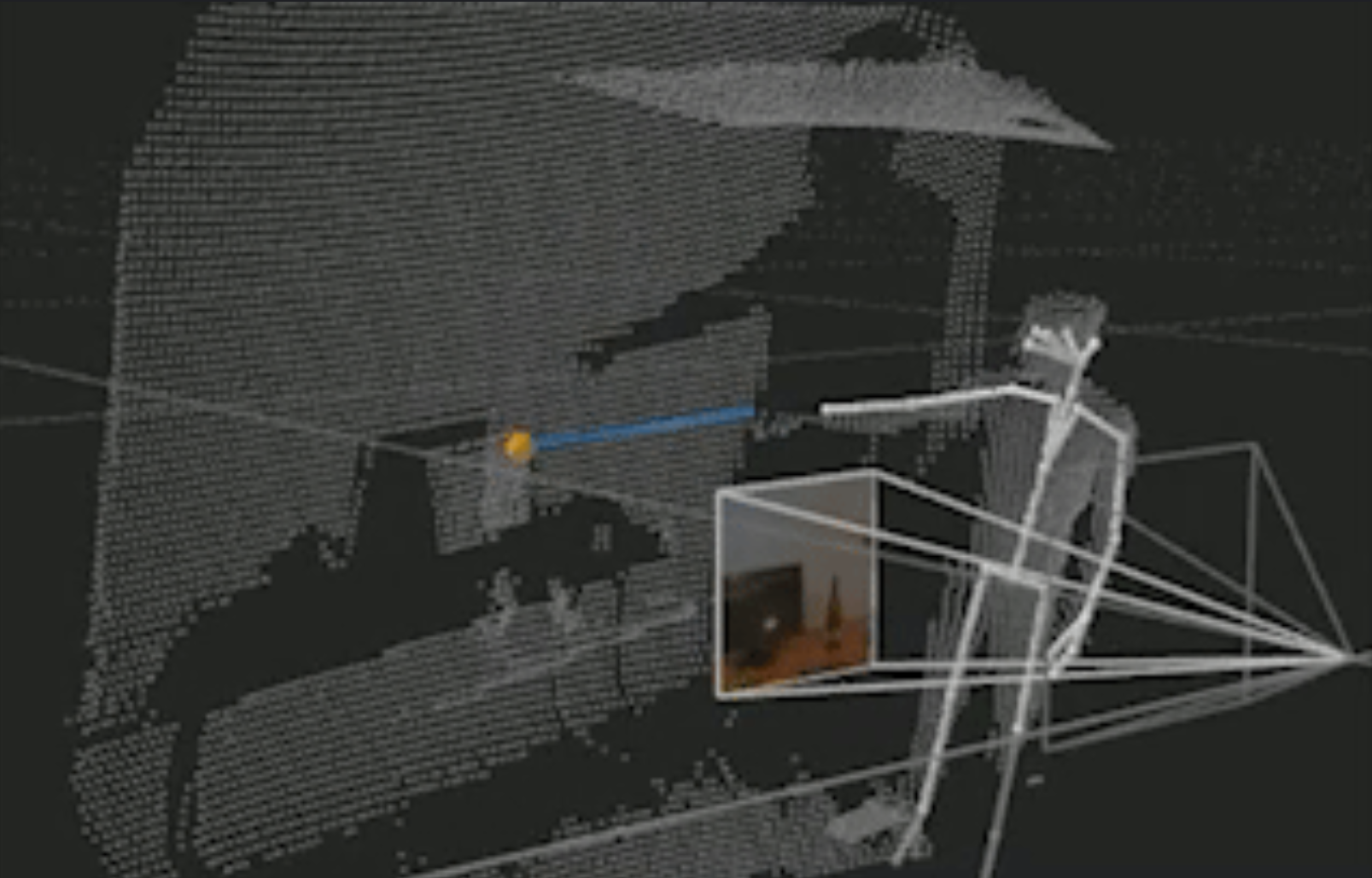
Depth-camera SLAM
Autonomously navigating indoors, where GPS and maps are not available, requires a robot to build and maintain a map of the environment by itself, a problem known as Simultaneous Localization and Mapping (SLAM). Traditionally this has been solved using accurate but expensive laser range scanners (LIDARs). We developed a complete mapping and navigation system that uses a commodity depth sensor like Microsoft Kinect as its sole source of range data instead, and showed that it achieves performance comparable to state-of-the-art systems that use laser scanners. Commodity depth sensors are inexpensive, easy to use and have high resolution, but suffer from high noise, shorter range and a limiting field of view. Despite these limitations, our method generates accurate 2D maps of large spaces, enabling robust navigation in changing and dynamic environments (project page, paper).